
רבים מסתמכים על תואר שני במשפטים (LLM) גם לביצוע פעולות מתמטיות. גישה זו אינה עובדת.
הנקודה היא פשוטה: מודלים לשוניים גדולים (LLMs) לא באמת יודעים איך להכפיל. לפעמים הם יכולים לקבל את התוצאה הנכונה, בדיוק כמו שאני אולי יודע את הערך של פאי בעל פה. אבל זה לא אומר שאני מתמטיקאי, וגם לא ש-LLMs באמת יודעים איך לעשות מתמטיקה.
דוגמה מעשית
דוגמה: 49858 *5994949 = 298896167242 תוצאה זו תמיד זהה; אין דרך אמצע. זה נכון או לא נכון.
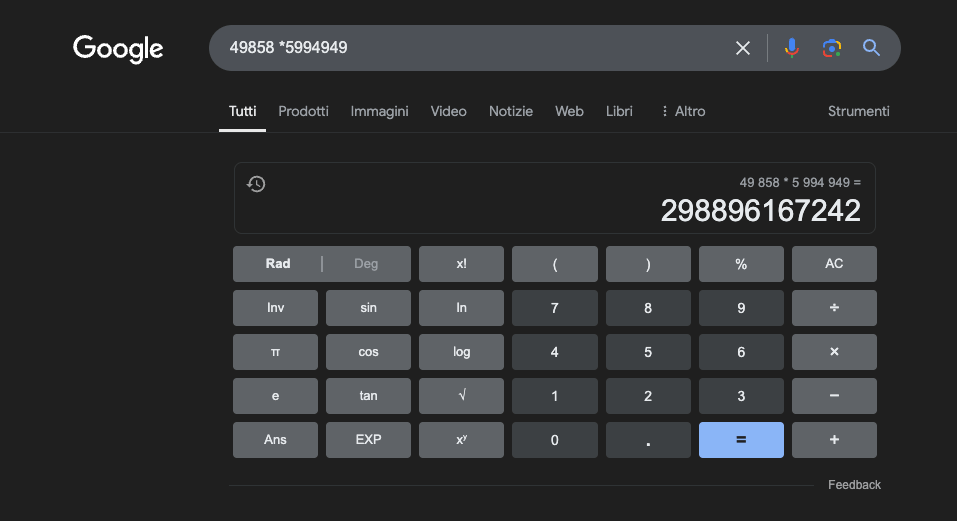
אפילו עם הכשרה מקיפה המתמקדת במתמטיקה, המודלים הטובים ביותר יכולים לפתור נכון רק חלק קטן מהחישובים. מחשבון כיס פשוט, לעומת זאת, משיג 100% מהתוצאות נכונות, בכל פעם. וככל שהמספרים גדולים יותר, כך הביצועים של המודלים לתואר שני (LLM) גרועים יותר.
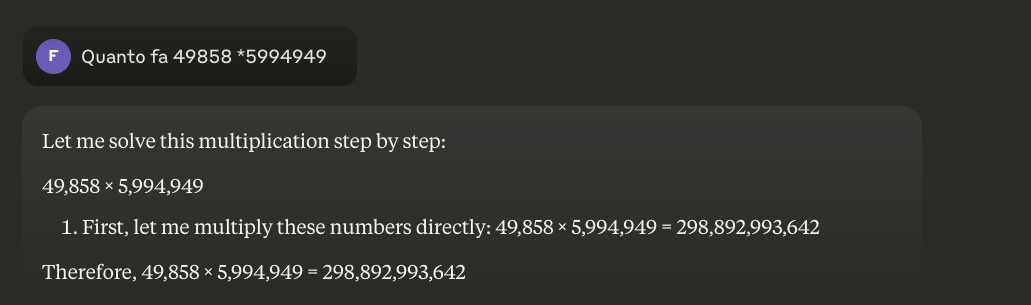
האם ניתן לפתור את הבעיה הזו?
הבעיה הבסיסית היא שמודלים אלה לומדים על ידי דמיון, לא על ידי הבנה. הם מתפקדים בצורה הטובה ביותר בבעיות דומות לאלה שעליהן אומנו, אך הם לעולם לא מפתחים הבנה אמיתית של מה שהם אומרים.
למי שרוצה ללמוד עוד, אני ממליץ על המאמר הזה בנושא " איך עובד תואר שני במשפטים ".
מחשבון, לעומת זאת, משתמש באלגוריתם מדויק שתוכנת לביצוע הפעולה המתמטית.
זו הסיבה שלעולם אסור לנו להסתמך לחלוטין על תוכניות לימודי משפטים (LLM) לחישובים מתמטיים: אפילו בתנאים הטובים ביותר, עם כמויות עצומות של נתוני אימון מיוחדים, הן לא מצליחות להבטיח אמינות אפילו בפעולות הבסיסיות ביותר. גישה היברידית עשויה לעבוד, אך תוכניות לימודי משפטים לבדן אינן מספיקות. אולי גישה זו תשמש לפתרון מה שנקרא "בעיית התות ".
יישומים של תואר ראשון במשפטים (LLM) בלימודי מתמטיקה
בהקשר החינוכי, סטודנטים לתואר שני במשפטים יכולים לשמש כמדריכים מותאמים אישית, המסוגלים להתאים הסברים לרמת ההבנה של הסטודנט. לדוגמה, כאשר סטודנט מתמודד עם בעיית חשבון דיפרנציאלי, התואר השני יכול לפרק את ההיגיון לשלבים פשוטים יותר, ולספק הסברים מפורטים לכל שלב בתהליך הפתרון. גישה זו מסייעת לבנות הבנה מוצקה של מושגים בסיסיים.
היבט מעניין במיוחד הוא יכולתו של התואר השני במשפטים (LLM) לייצר דוגמאות רלוונטיות ומגוונות. אם סטודנט מנסה להבין את מושג הגבולות, התואר השני יכול להציג תרחישים מתמטיים שונים, החל ממקרים פשוטים ועובר למצבים מורכבים יותר, ובכך לאפשר הבנה הדרגתית של המושג.
יישום מבטיח אחד הוא השימוש בתואר ראשון במשפטים (LLM) כדי לתרגם מושגים מתמטיים מורכבים לשפה טבעית נגישה יותר. זה מקל על תקשורת המתמטיקה לקהל רחב יותר ועשוי לסייע להתגבר על המכשול המסורתי לכניסה לתחום זה.
תואר שני במשפטים (LLMs) יכול גם לסייע בהכנת חומרי הוראה, יצירת תרגילים ברמת קושי משתנה ומתן משוב מפורט על הפתרונות המוצעים על ידי התלמידים. זה מאפשר למורים להתאים אישית טוב יותר את מסע הלמידה של תלמידיהם.
היתרון האמיתי
באופן כללי יותר, חשוב גם לקחת בחשבון את ה"סבלנות" הקיצונית הנדרשת כדי לעזור אפילו לתלמיד הכי פחות מוכשר ללמוד: במקרה זה, היעדר רגש עוזר. למרות זאת, אפילו בינה מלאכותית לפעמים "מאבדת סבלנות". ראו דוגמה "משעשעת" זו.
עדכון 2025: מודלים של חשיבה והגישה ההיברידית
2024-2025 הביאו התפתחויות משמעותיות עם הגעתם של מה שנקרא "מודלים של חשיבה" כמו OpenAI o1 ו- deepseek R1. מודלים אלה השיגו תוצאות מרשימות במבחנים מתמטיים: o1 פתר 83% מבעיות האולימפיאדה המתמטית הבינלאומית בצורה נכונה, בהשוואה ל-13% עבור GPT-4o. אך היזהרו: הם לא פתרו את הבעיה הבסיסית שתוארה לעיל.
בעיית התות - ספירת ה-'ר' במילה "תות" - ממחישה בצורה מושלמת את המגבלה המתמשכת. o1 פותר אותה נכון לאחר מספר שניות של "הנמקה", אבל אם מבקשים ממנו לכתוב פסקה שבה האות השנייה של כל משפט מאייתת את המילה "CODE", הוא נכשל. o1-pro, הגרסה שעולה 200 דולר לחודש, פותר אותה... לאחר 4 דקות של עיבוד. DeepSeek R1 ודגמים עדכניים אחרים עדיין טועים בספירה הבסיסית. נכון לפברואר 2025, Mistral עדיין אמרה לכם שיש רק שתי 'ר' במילה "תות".
הטריק המתפתח הוא גישה היברידית: כאשר הם צריכים להכפיל 49858 ב-5994949, המודלים המתקדמים ביותר כבר לא מנסים "לנחש" את התוצאה על סמך קווי דמיון לחישובים שנצפו במהלך האימון. במקום זאת, הם קוראים למחשבון או מפעילים קוד פייתון - בדיוק כמו אדם אינטליגנטי שמכיר את מגבלותיו.
"שימוש בכלים" זה מייצג שינוי פרדיגמה: בינה מלאכותית לא חייבת להיות מסוגלת לעשות הכל בעצמה, אלא חייבת להיות מסוגלת לתזמר את הכלים הנכונים. מודלים של חשיבה משלבים יכולות לשוניות להבנת הבעיה, חשיבה שלב אחר שלב לתכנון הפתרון, והאצלת סמכויות לכלים ייעודיים (מחשבונים, מפרשי פייתון, מסדי נתונים) לביצוע מדויק.
הלקח? סטודנטים לתואר ראשון במשפטים (LLM) של 2025 שימושיים יותר במתמטיקה לא משום שהם "למדו" להכפיל - הם עדיין לא באמת עשו זאת - אלא משום שחלקם החלו להבין מתי להאציל את סמכויות הכפל לאלו שבאמת יודעים איך לעשות זאת. הבעיה הבסיסית נותרה: הם פועלים על סמך דמיון סטטיסטי, לא על סמך הבנה אלגוריתמית. מחשבון של חמישה יורו נותר אמין לאין שיעור לחישובים מדויקים.

.svg)
.svg)
.svg)
.jpeg)





